Given the global distribution of our telescopes and the wide array of instruments, our pipeline must be fully automated and fault tolerant to minimize the need for human intervention. To achieve this, we have developed the BANZAI pipeline infrastructure. The code is open source and available at https://github.com/LCOGT/banzai. We currently process all of our imaging data in real time with data available to users within a few minutes of shutter close. The BANZAI code is described in more detail in McCully et al., arXiv, 1811.04163. The code is designed to be modular and useful for many types of astronomical data.
We are currently retiring a commissioning pipeline that was written in IDL to process NRES data. We have adapted BANZAI the code to reduce spectroscopic data as well. We have recently overhauled the infrastructure: we have added the propagation of pixel-by-pixel uncertainties to the final data products and update the pipeline to be easily scaled in cloud computing environments.
The code to process the high-resolution spectra from NRES is also open source and can be found at https://github.com/LCOGT/banzai-nres. Nearly all of the plumbing code is handled by BANZAI, so code specifically for spectroscopic reduction is all that is necessary in the BANZAI-NRES repository.
We stack bias and dark frames in the usual way. We use the median absolute deviation of each pixel between the individual frames to identify cosmic rays and other bad pixel outliers. We then take the mean of the remaining pixels so that continuous distribution statistics still apply (i.e. we can assume that the uncertainties add in quadrature).
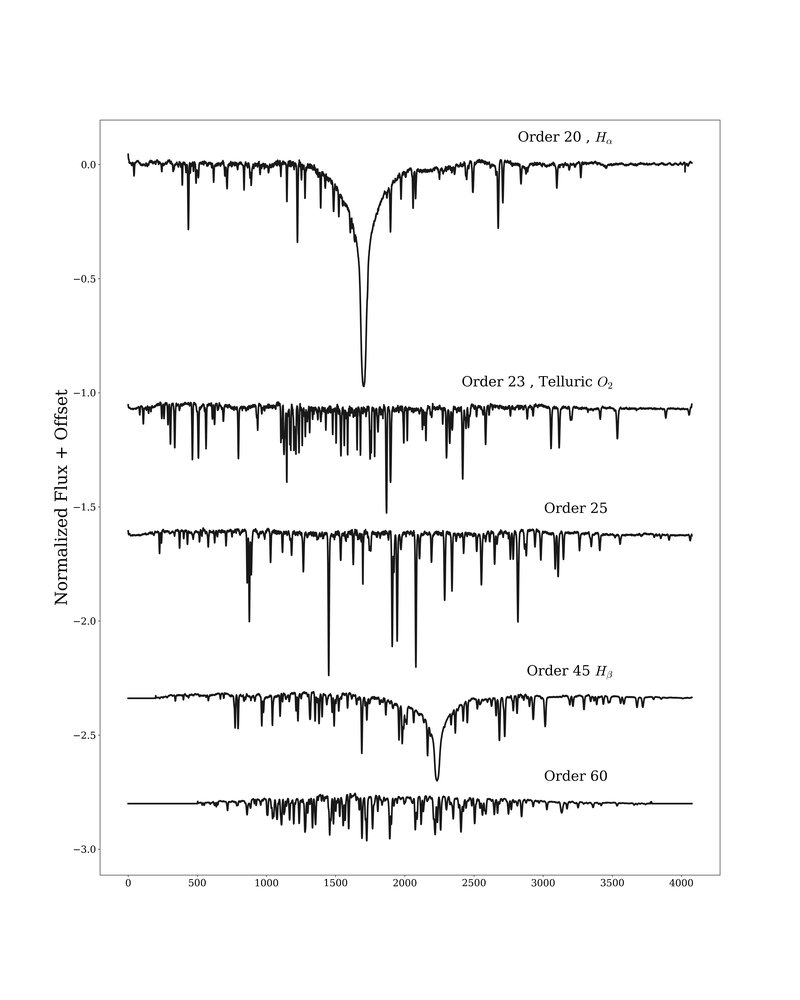
We use lamp flat field exposures to identify the locations of the orders for each fiber that is lit (NRES has 3 fibers: one from each of two telescopes and a calibration unit fiber). We automatically measure the locations by using a maximum filter, dilating the max mask, and grouping connected pixels using scipy.ndimage. Once we have identified where the orders lie on the chip, we model the blaze by summing the pixels along each column in each extraction order. The remaining variations are due to the profile and pixel-to-pixel variations. We do not attempt to disentangle these variations currently, but will investigate this in the future.
To wavelength calibrate the spectra, we take ThAr arc-lamp exposures. We have opted to produce a wavelength solution on the non-extracted, 2-D frame. The line spread function of NRES is elliptical and the orientation of the ellipse varies across the chip, so by working in the 2-D frame, we can (at least partially) recover the lost wavelength resolution necessary for high precision RVs and other applications that require high spectral resolution. We identify arc lines using an algorithm that is similar to detecting stars, e.g. DAOPhot (Stetson 1987, PASP, 99, 191S) or Source Extractor (Bertin & Arnouts, 1996, A&A Supplement, 317, 393).
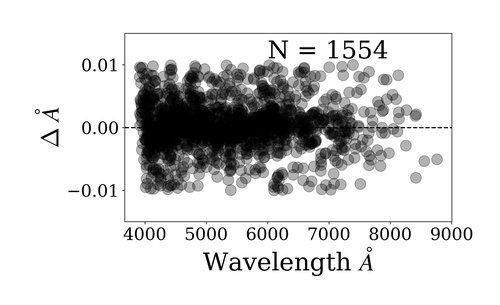
To find the mapping between pixel and wavelength, we employ the algorithm presented in Brandt et al. 2019 (arXiv 1910.08079) that leverages the overlap between orders to generate an entirely automatic wavelength solution. We are currently able to achieve wavelength calibration to 0.005 Angstroms RMS. This corresponds to 10 m/s overall precision for the number of arc lines that we identify.
Once we have the full 2-D wavelength solution, we can bin (aka extract) however we see fit. We currently use optimal extraction weights from Horne (1986, 98, 609).
To measure radial velocities and classify stellar spectra, we plan to cross-correlate our spectra with the Phoenix stellar models (Husser et al., 2013, A&A, 553, A6). Our prototypes are able to achieve 40 m/s precision already. Our goal is to produce 10 m/s precision in regular operations by the end of Q3 2020, and to achieve < 5 m/s, near the design specification, by the end of Q1 2021. We will continue to add further improvements in algorithms and new features like flux calibration in the future.
We will provide data from all stages of processing to allow our end users to add any custom analysis that is necessary for their science case. We plan to include stacked bias, dark, lamp flat, and arc lamp frames, 2-D wavelength solutions, 2-D extraction weights, and wavelength-calibrated 1-D spectra, all of which include variance estimates. We will also include high level science products including an RV measurement, spectral classification, and the Ca H&K-based stellar activity index.